![]()
什么是 GEO、ENA 和 SRA?
在基因组学、转录组学和单细胞研究中,公开数据库是科研的宝藏。不同数据库特点略有不同:
| | | |
|---|
| GEO (Gene Expression Omnibus) | | 表达矩阵、微阵列、RNA-seq、ChIP-seq | 方便获取已处理的表达矩阵和样本信息,适合复现分析和教学 |
| ENA (European Nucleotide Archive) | | 原始测序数据(FASTQ)、DNA/RNA/宏基因组 | 数据全面,支持 FTP / Aspera 高速下载,适合大规模原始数据分析 |
| SRA (Sequence Read Archive) | | | 与 ENA 数据高度互通,是获取原始测序 reads 的重要来源,支持命令行和工具下载 |
为什么要用这些数据库?
教学练习:用真实数据训练 RNA-seq、GWAS、单细胞分析技能
如何快速下载数据?
(1)GEO 数据下载
GEO 提供 GEOquery R 包,可直接获取表达矩阵和样本信息:
# 安装 GEOquery
if(!require(GEOquery))
BiocManager::install("GEOquery")
library(GEOquery)
# 下载 GEO 系列数据
gse <- getGEO("GSEXXXXX", GSEMatrix = TRUE)
exprSet <- exprs(gse[[1]])
# 提取表达矩阵
phenoData <- pData(gse[[1]])
# 提取样本信息
# 查看数据
head(exprSet)
head(phenoData)
GEO 页面也提供 TXT / SOFT 文件 直接下载,适合非程序用户。
(2)ENA 数据下载
ENA 原始数据通常为 FASTQ 文件,可使用 Aspera / FTP / wget 下载:
方法一:Aspera 快速下载
ascp -QT -l 300m -P33001 -i ~/.aspera/connect/etc/asperaweb_id_dsa.openssh \ era-fasp@fasp.sra.ebi.ac.uk:/vol1/fastq/ERRXXXX/ERRXXXXXX/ERRXXXXXX.fastq.gz ./
方法二:批量下载
# 创建包含 Run ID 的列表 run_list.txt
for id in $(cat run_list.txt); do ascp -QT -l 300m -P33001 -i ~/.aspera/connect/etc/asperaweb_id_dsa.openssh \ era-fasp@fasp.sra.ebi.ac.uk:/vol1/fastq/$id/$id.fastq.gz ./ done
注意:Aspera 速度快,但需安装 Aspera Connect 并配置密钥。ENA 网站也可用 FTP/HTTPS 下载。
(3)SRA 数据下载
SRA 数据也可通过 NCBI SRA Toolkit 下载,支持 FASTQ 格式:
# 安装 SRA Toolkit 并设置路径
# 下载单个样本 (以 SRRXXXXX 为例)
prefetch SRRXXXXX
# 转换为 FASTQ
fastq-dump --split-files SRRXXXXX
SRA Toolkit 支持批量下载,用 --option-file 指定一个包含多个 SRR 的文本文件。
示例
表达矩阵和样本信息,原始fastq通过点击SRA RUn SELECTOR跳转到SRA网站选择样本后,点击accession list 获得样本SRR编号,通过SRA Toolkit下载或者到ENA数据库检索BioProject编号:PRJNA1037470选择Aspera获取下载链接,(如:fasp.sra.ebi.ac.uk:/vol1/fastq/SRR267/038/SRR26767238/SRR26767238.fastq.gz)下载fastq文件,速度更快。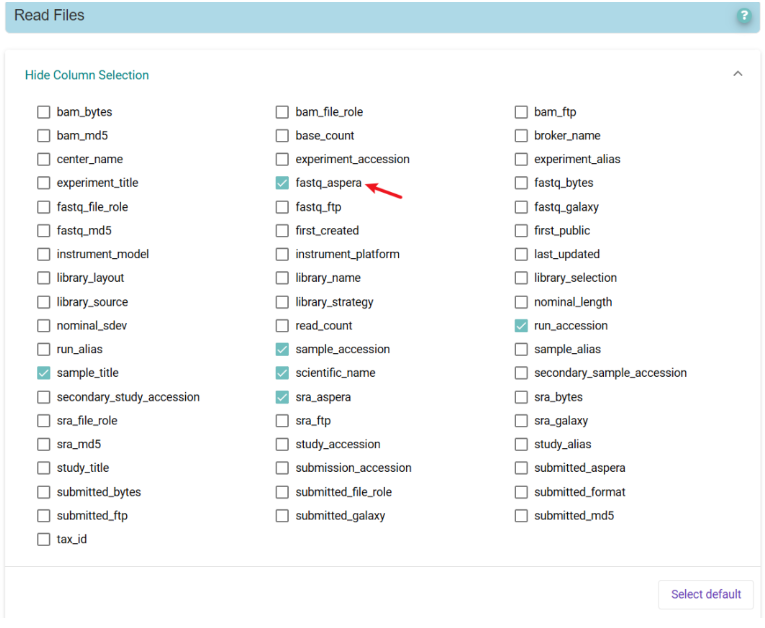
小结
使用 GEO 获取 表达矩阵,使用 ENA/SRA 获取 原始测序数据,可以快速搭建自己的分析流程。