英文标题
Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning
中文标题
基于原型跨模态对比学习的大词汇量法医病理分析
关键词
法医病理学、计算病理学、视觉语言模型(VLM)、自监督学习、跨模态融合、SongCi模型
研究背景
法医病理学是确定死因与死亡方式的关键环节,但传统尸检高度依赖经验、主观性强,且劳动密集、专家短缺。
近年来人工智能(AI)在临床病理学(如癌症诊断)中取得突破,但直接迁移到法医领域存在困难:
因此,作者提出了专为法医病理学设计的多模态模型——SongCi(取名自南宋法医学家宋慈)。
研究目的
构建一个能同时理解图像与文字描述、可执行开放词汇量法医诊断任务的AI模型,通过自监督学习方式让模型从海量未标注尸检图像和描述中学习特征,实现跨机构、跨器官的泛化分析。
方法概述
模型结构:
学到 933 个原型表示,用于捕捉典型尸体现象(如自溶、出血、纤维化等)。
- 负责理解肉眼观察描述(gross key findings)和诊断结果文本。
引入门控注意力机制(gated attention);
实现零样本诊断预测(zero-shot inference)。
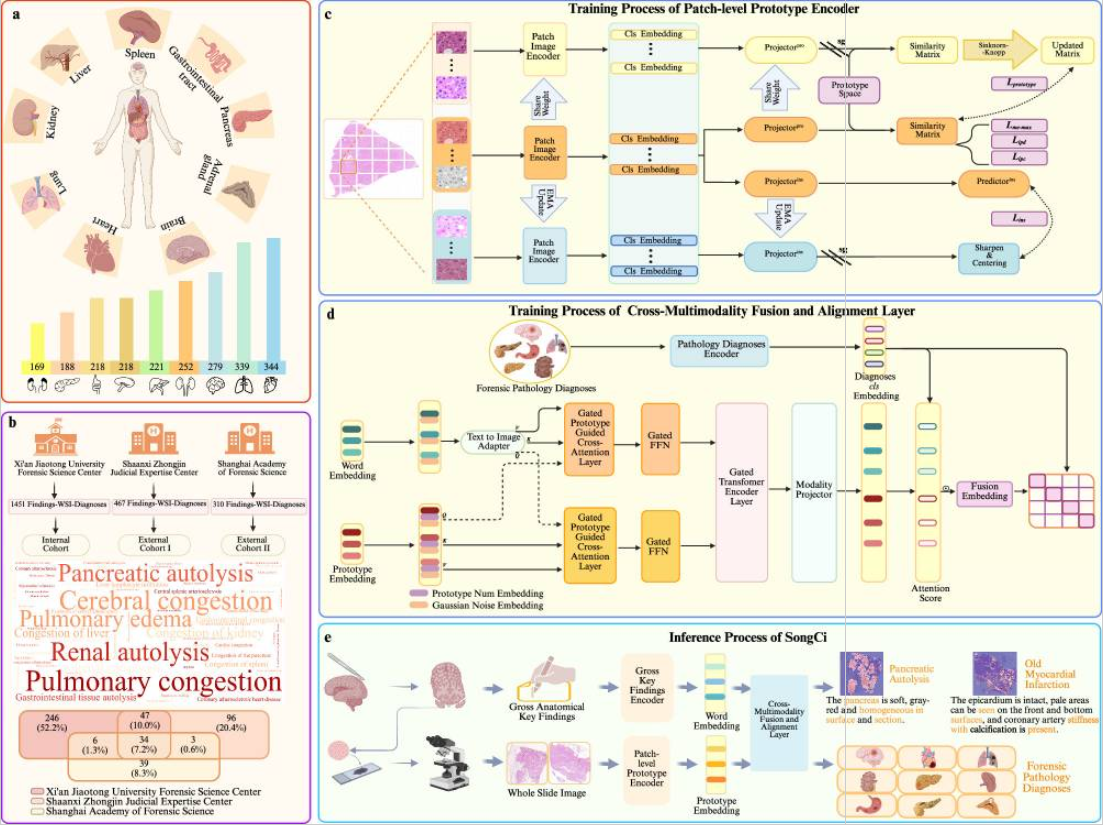
数据集
来源:三个法医学司法鉴定中心(西安交通大学、陕西中金司法鉴定中心、上海司法鉴定科学研究院);
覆盖 9 个器官(脑、心、肺、肝、肾、胰腺、脾、肾上腺、胃肠道);
主要结果
通过UMAP降维展示,SongCi能自动区分不同器官特征;
原型中既有特异性模式(如心肌肥厚、脑水肿),也有跨器官共享模式(如自溶、炎症、出血)。
在未标注条件下完成高质量组织分割,精度明显优于H2T与PANTHER聚类方法。
与六个最先进的视觉语言模型(IRENE、GIT、MCAT等)相比,SongCi在内部与外部数据集上召回率、精确度、IOU均领先10–20%;
在罕见诊断(low-frequency)与偏移任务(off-set)中表现尤为突出;
在100例外部验证样本中,SongCi的诊断准确度与高级法医(15年以上经验)相当;
SongCi能自动标注图像中关键病理区域与文字描述对应的关键词;
实现图像—文字双向可视化解释,辅助法医理解模型决策逻辑。
讨论与意义
SongCi 填补了法医病理学缺乏AI基础模型的空白;
同时可迁移到临床病理数据(如癌症诊断),在TCGA与CAMELYON数据集上表现良好。
文章亮点
融合宏观与显微层面信息,能自动识别、解释病理特征;
原文链接:Shen, C., Lian, C., Zhang, W. et al. Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning. Nat Commun 16, 6773 (2025). https://doi.org/10.1038/s41467-025-62060-x